Сегодня не будет серьёзных вещей, друзья. Сегодня будет программирование just for fun. Продолжаем следить за тем, как одна маленькая и глупая идея превращается в большое (но всё такое же глупое) приложение:)
В прошлый раз я рассказал о том, как я сделал простой экшэн для Альфреда, о том, как я залез по пояс в документацию по OAuth, взял в одну руку tcpdump, в другую — curl, а в третью — Python, и научился подписывать любой запрос с помощью OAuth без сторонних библиотек, и как затем получил расширение для хрома…
Сразу после этого я понял, что картинки нужно пропускать через очередь, чтобы не вываливать на бедных читателей большие порции картинок (редко и по многу). Я прикрутил простую очередь, из которой картинки выбираются раз в полчаса. Очередь хранится в localStorage. Полный код этого расширения можно найти у меня на гитхабе. Пользовался я этим расширением очень долго, до недавнего времени, пока меня окончательно не добили два его основных недостатка. Во- первых, это решение полностью зависит от моего макбука: чтобы раздача шла, он должен быть включен, на нём должен быть запущен Хром и он должен быть всегда подключен к интернету. Это далеко не всегда выполняется при моём кочевом образе жизни и работы. Во-вторых, эта система никак мне не помогает с поиском дубликатов. После третьей тысячи картинок держать всё в голове уже становится невозможно.
Система подросла и превратилась в нечто более сложное:) Плагин для Хрома упростился до простого POST запроса на сервер: отсылает ссылку на картинку и идентификатор пользователя (кстати, теперь стало возможно добавлять доверенных людей, которые могут предлагать свои картинки). На сервере ссылка попадает в Resque очередь. Она скачивается на сервер, по ней строится хэш (об этом чуть ниже), создаётся её уменьшенная превьюшка, первоначальная картинка удаляется, затем по полученному хэшу происходит поиск дубликатов. Обработанная картинка встаёт в очередь на публикацию, или в очередь на модерацию (если она пришла не от меня или есть подозрения на дубликаты). Из очереди на публикацию по одной картинке раз в полчаса/час вынимает Resque Scheduler.
Поскольку я хотел сделать поиск дубликатов, мне нужно было наполнить базу уже опубликованными картинками. Предыдущая версия приложения удаляла ссылку из очереди сразу после отправки её в твиттер. А значит единственное место, где есть все мои картинки — это сама лента твиттера. Здесь меня ждало небольшое горе. API твиттера позволяет получить только последние 3200 твитов (16 страниц по 200 твитов), а к тому моменту я успел напостить около 4000 картинок. Про самые ранние восемь сотен картинок пришлось забыть. Нужно пройтись по твитам, выцепить оттуда сокращённую ссылку, сходить с ней на сервер, получить 304 и сохранить развёрнутую ссылку в файлик вместе со временем публикации.
require 'twitter'
require 'net/http'
user_name = 'sourceoftits'
f = File.new("#{Rails.root}/db/published.txt", 'w')
(1..16).each do |page|
Twitter.user_timeline(user_name, :page => page, :count => 200).each do |tweet|
if tweet.text =~ /(http:\/\/\S*)/
uri = URI.parse($1)
http = Net::HTTP.new(uri.host, uri.port)
http.start() do |http|
req = Net::HTTP::Get.new(uri.path)
response = http.request(req)
real_link = response['location']
f.write "#{tweet.created_at.to_i}|#{real_link}\n"
end
end
end
end
f.close
Мои основные источники картинок — Вконтактик и Тумблер. Мне повезло, ссылки на них даже через полгода-год остаются валидными. С Вконтактом ещё веселее: он за это время переехал на домен vk.com и несколько раз поменял структуру хранения фоток. Однако все старые прямые ссылки на фотки остались рабочими.
Один из самых простых способов — поиск на основе перцептивного хэша. Для каждой картинки вычисляется хэш (fingerprint) и сохраняется в БД. При добавлении новой картинки её хэш сравнивается со всеми уже существующими в базе. Если расстояние Хэмминга между хэшами меньше определённого порога (например, 12) — картинки считаются похожими. Искать в БД по расстоянию Хэмминга, насколько мне известно, умеют далеко не все. Например, Postgres — с помощью расширения pg_similarity. В моей MongoDB такой финт ушами не пройдёт, поэтому я решил предрассчитывать расстояния заранее и хранить их в Redis (он в системе всё равно уже есть — для Resque). Sorted Set для этого хорошо подойдёт. Ключом будет расстояние, значением — ID картинки. Сначала я использовал гем similie. Но на выборке в 3500 картинок он выдал 300 абсолютно одинаковых хэшей. Такая точность никуда не годится. Затем мне попался гем phashion, обёртка над библиотекой pHash. С адекватностью хэшей у него всё в порядке, но есть два мелких косячка. Во- первых, fingerprint возвращает беззнаковый uint64, который не влазит в знаковый int64 в Mongo. Во-вторых, он возвращает 0 вместо хэша на некоторых PNG в Linux (на продакшене). На девелоперской машине под OS X те же самые файлы обрабатываются корректно. Думаю, проблема в libpng (которую, кстати пришлось на продакшене подключать в гем вручную и пересобирать C extension заново). Я быстро решил проблему конвертированием PNG в JPEG файлы, благо RMagick в системе уже был (нужен для Carrierwave).
def process_image
uri = URI.parse(self.link)
http = Net::HTTP.new(uri.host, uri.port)
http.start() do |http|
req = Net::HTTP::Get.new(uri.path)
response = http.request(req)
tempfile = Tempfile.new(File.basename(uri.path))
begin
File.open(tempfile.path, 'wb') { |f| f.write response.body }
if File.extname(uri.path) =~ /\.png/i
thumb = Magick::Image.read(tempfile.path).first
thumb.format = 'JPEG'
thumb.write tempfile.path
end
phasion = Phashion::Image.new(tempfile.path)
self.fingerprint = '%016x' % phasion.fingerprint
self.preview = tempfile
self.preview.store!
self.size = tempfile.size
ensure
tempfile.close
tempfile.unlink
end
end
end
def calc_distances(two_way=true)
Tits.where(:_id.ne => id).each do |tits|
distance = Phashion.hamming_distance(fingerprint.hex, tits.fingerprint.hex)
if distance <= Settings.hamming_threshold
redis.zadd "distances:#{id}", distance, tits.id
redis.zadd "distances:#{tits.id}", distance, id if two_way
end
end
end
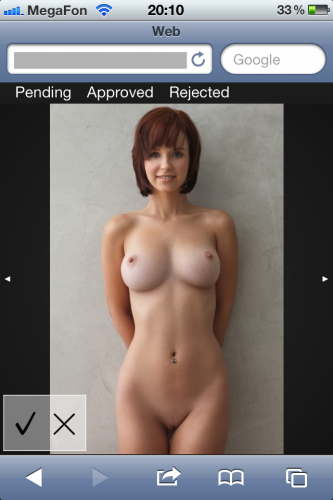
Основные экраны приложения сделаны в виде галереи на основе Фоторамы. Её пришлось немного допилить напильником, чтобы разместить сверху страницы небольшое меню и чтобы она правильно вела себя и на айфоне и на десктопе при любых разрешениях картинок.
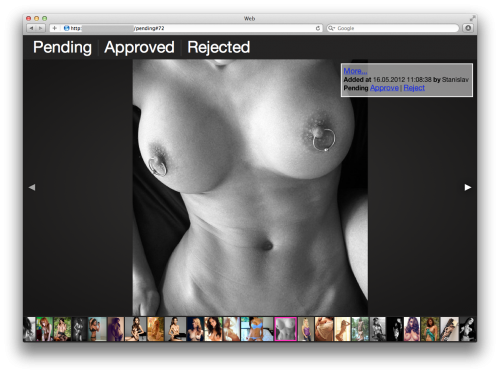
В отличие от десктопной версии, в мобильной нет ленты с превьюшками внизу, и сильно упрощена панелька с информацией. Всё это сделано только для экономии места на экране. Похожие картинки, если такие есть, отображаются на панельке с прочей информацией. По цвету рамки можно определить, в каком состоянии находится картинка-дубликат. Зелёная рамка — картинка уже была опубликована, красная — отклонена, белая означает, что дубликат тоже стоит в очереди на модерацию.

Разместить всё это я решил на Амазоне. Весь сервер спокойно влазит в бесплатный t1.micro. А базу данных можно разместить на MongoHQ, бесплатных 16Мб хватит за глаза (примерно на 35К записей). Бежит сиськомашина на Ubuntu 10.04, Nginx+Passenger, здесь же установлен Redis, один воркер Resque и один Resque-Scheduler. За ребятами следит грозный Monit. Деплоил с помощью Standup.
Хочу избавиться от привязки к своему браузеру (Chrome Extension для отправки ссылок на сервер). Было бы здорово встроить RSS-ридер прямо в веб-интерфейс приложения и аппрувить картинки не отходя от кассы. Именно для этого я делал мобильную версию — чтобы разбирать картинки в любом месте, когда выдалась свободная минутка. Проблема только с Вконтактиком. У него нет официальной RSS ленты, зато есть API и разные самодельные RSS надстройки (но только для публичных групп). Буду признателен за советы по этой проблеме.
© 2011-2022 - Станислав Спиридонов